🎮 Toy example
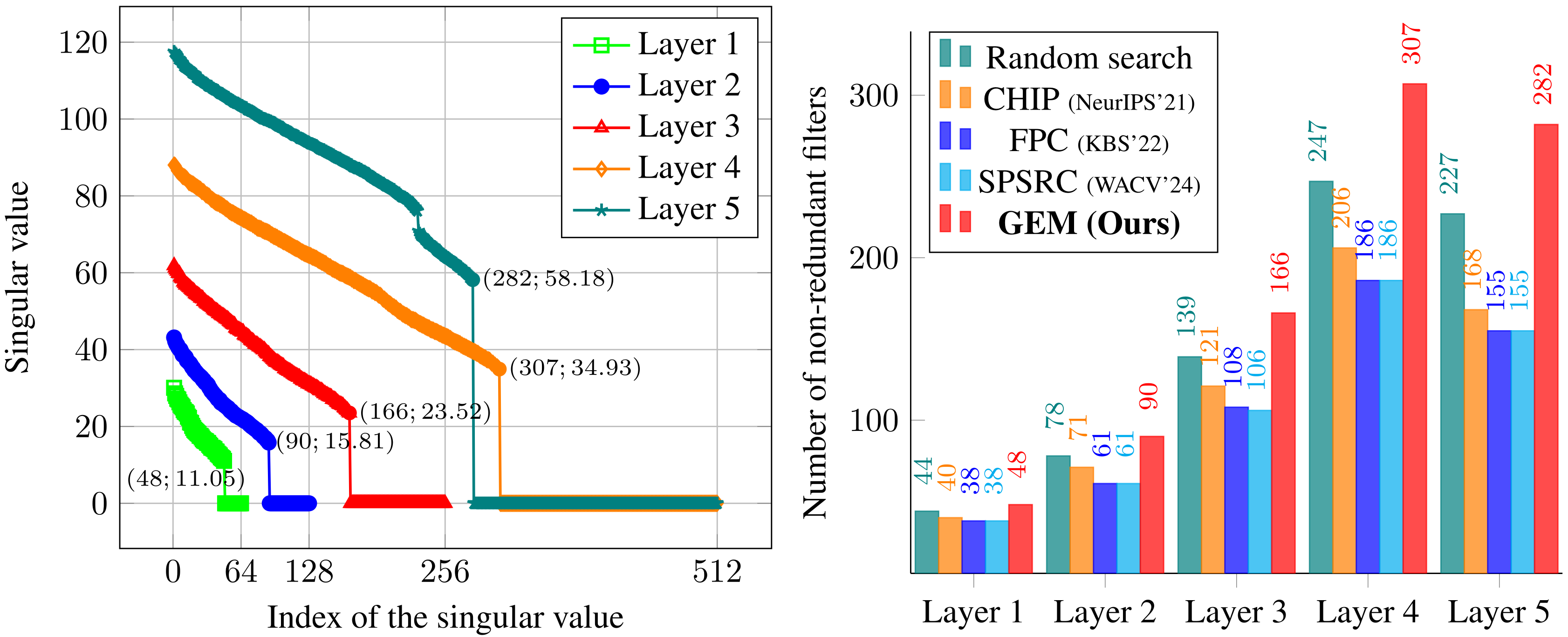
This paper proposes a method that leverages tools from linear and multilinear algebra to provide a new solution for automated filter pruning. We propose to detect network redundancy hinging on the dynamics of singular values and the use of the nuclear norm. We illuminate the intricate relationship between filter redundancy within neural networks and the observable variations in their singular values. To illustrate the rationale of our proposed approaches, we create a synthetic dataset, dubbed as SVGG, which includes an original model that mimics the architecture of the VGG network with \(L=5\), \(d_l= 3\) and \(\{C_l\}_{l=1}^L = \{64, 128, 256, 512, 512\}\). We choose the redundant rates (the ratio of the number of redundant filters to the total number of filters, i.e., \(\frac{C_l-N_l}{C_l}\)) of these layers sequentially as \(\{0.25, 0.3, 0.35, 0.4, 0.45\}\), thus \(\{N_l\}_{l=1}^L = \{48, 90, 166, 307, 282\}\), and the number of retained filters \(N=893\). In the \(l\)-th layer, we init \(N_l\) core filters with the standard normal distribution while the remaining redundant filters are copied from the core filters with a small noise of variance \(\epsilon = 0.01\). The "multilinear" singular values are visualized as follows. One should note that the overparameterized model contains many near-zero singular values, indicating redundancy. The random search approach, CHIP, FPC, and SPSRC yield suboptimal results, whereas GEM successfully identifies all unique filters, achieving 100% accuracy comparable to the complete search, with reduced computational overhead.